
Or, that should be, proxies for late-Georgian satires. For – of course… – textual descriptions of visual sources are not the visual sources themselves and three of the five graphs below are derived from the proxies as opposed to the prints. To recap from previous posts these prints are late-Georgian satires and their textual proxies are volumes five to eleven of the Catalogue of Political and Personal Satires Preserved in the Department of Prints and Drawings in the British Museum (hereafter BMSat – the data can be downloaded using this query on this interface), written by Mary Dorothy George, 1935-1954. As my research agenda has firmed up into an exploration of speech and gender in late-Georgian prints and their textual proxies, I have simultaneously begun to get my teeth into R, a programming language and software environment for statistical computing. I have been meaning to get back to R for some time. When I talk to scientists who work with data, it is more often than not mentioned. And having played around with it a little after attending a Software Carpentry event in 2013, Lincoln Mullen’s recent publication of a work in progress guide to using R for historical research gave me to impetus to go back.
So how has this been useful? In short, very. R not only enables the production of clean, crisp graphs but the use of code to build them makes those graphs reproducible, verifiable, and easy to tweak. There is a learning curve compared to using Open Office or Excel to build graphs, but the pay-off is worth it – especially in terms of flexibility and control (all the usual benefits of writing code to do stuff).
So what are these five graphs?
Figure One (code, data) shows the relative annual frequency (count divided by total prints per year) of the words ‘man’, ‘woman’, ‘men’, ‘women’, and say-lemma (say, says, saying, and said) in BMSat between 1780 and 1810. Each thin line is a smoothed mean, the area around it a margin of error. The output is as expected: ‘man’ occurs roughly twice as often as ‘woman’; ‘men’ roughly twice as often as ‘women’. It is notable that by 1810 ‘man’ is well into a decade long decline. Say-lemma is there for context. It is much more spiky and it suggests that there is no obvious correlation between say-lemma and ‘man’, ‘woman’, ‘men’, or ‘women’. This is significant, as we shall see.
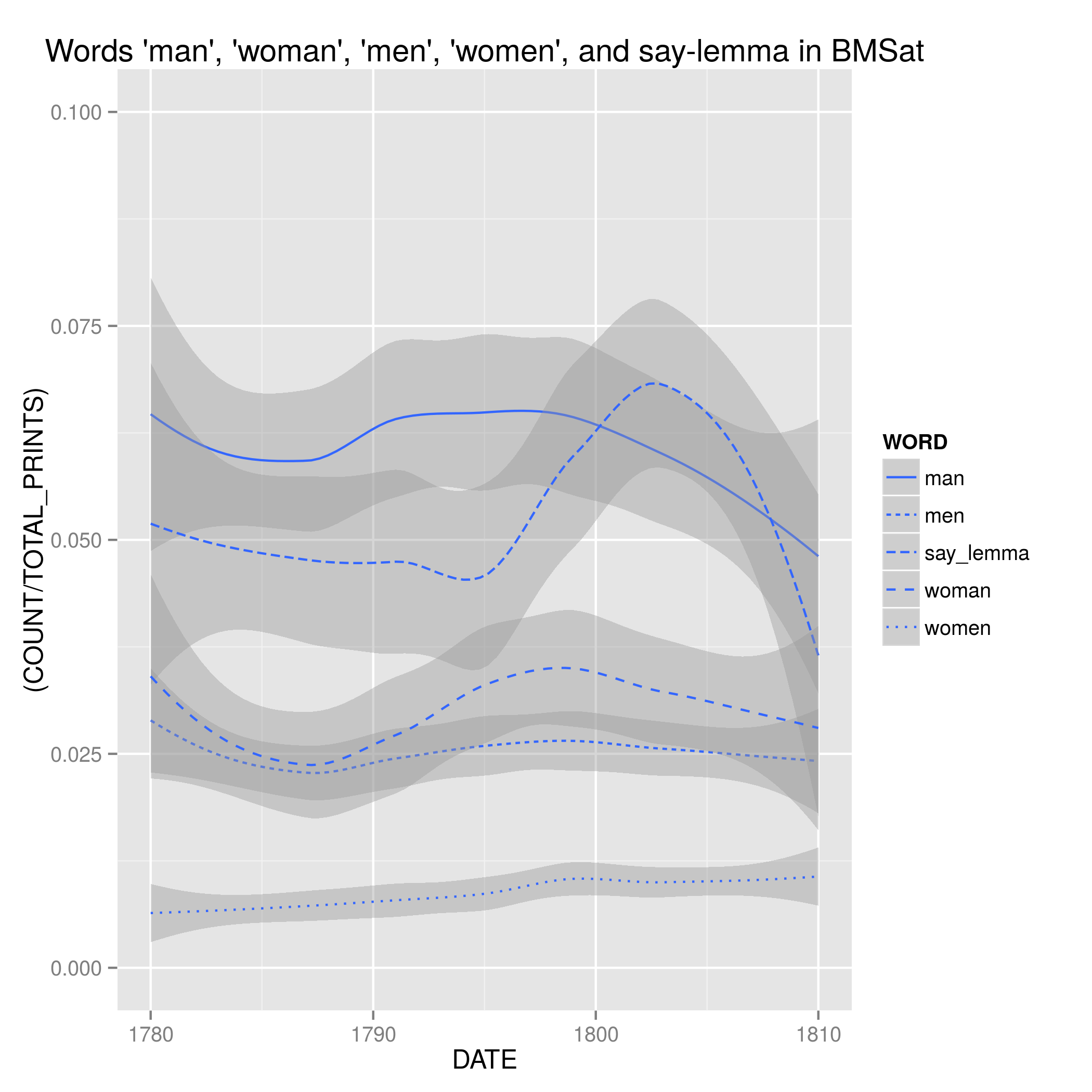

Figure Two (code, data) suggests a similar pattern. It shows the relative annual frequency (again count divided by total prints per year) of the most common male and female category words in BMSat. The category words in question are:
- male: boy, boys, brother, buck, countryman, duke, gentlemen, husband, lads, lord, male, man, master, measter, men, mr, sir
- female: duchess, female, ladies, lady, mrs, ms, wife, woman, women
These peak around 1800 and decline thereafter, sharply in the case of male words.

So what we have in both Figures One and Two are signifiers of male and femaleness declining in BMSat after 1800. But it does not follow from this that male and female speech acts were also in decline. Indeed, Figure Three (code, data) shows the annual mean T-score (a measure of word-proximity) of the most common male and female category words that appear 5 words left and 5 words right of say-lemma in BMSat. In short, the graph shows co-occurrence over time. And as the graph suggests, even though per Figures One and Two the relative frequencies of ‘man’, ‘woman’, ‘men’, and ‘women’ in BMSat were declining or stalling circa 1800-1810, male and female category words were simultaneously becoming more attached to speech acts.
One potential explanation for category words falling overall whilst gaining strength as collocates of ‘say-lemma’ relates to what is happening with named people, data not captured by the measures I’ve used thus far.
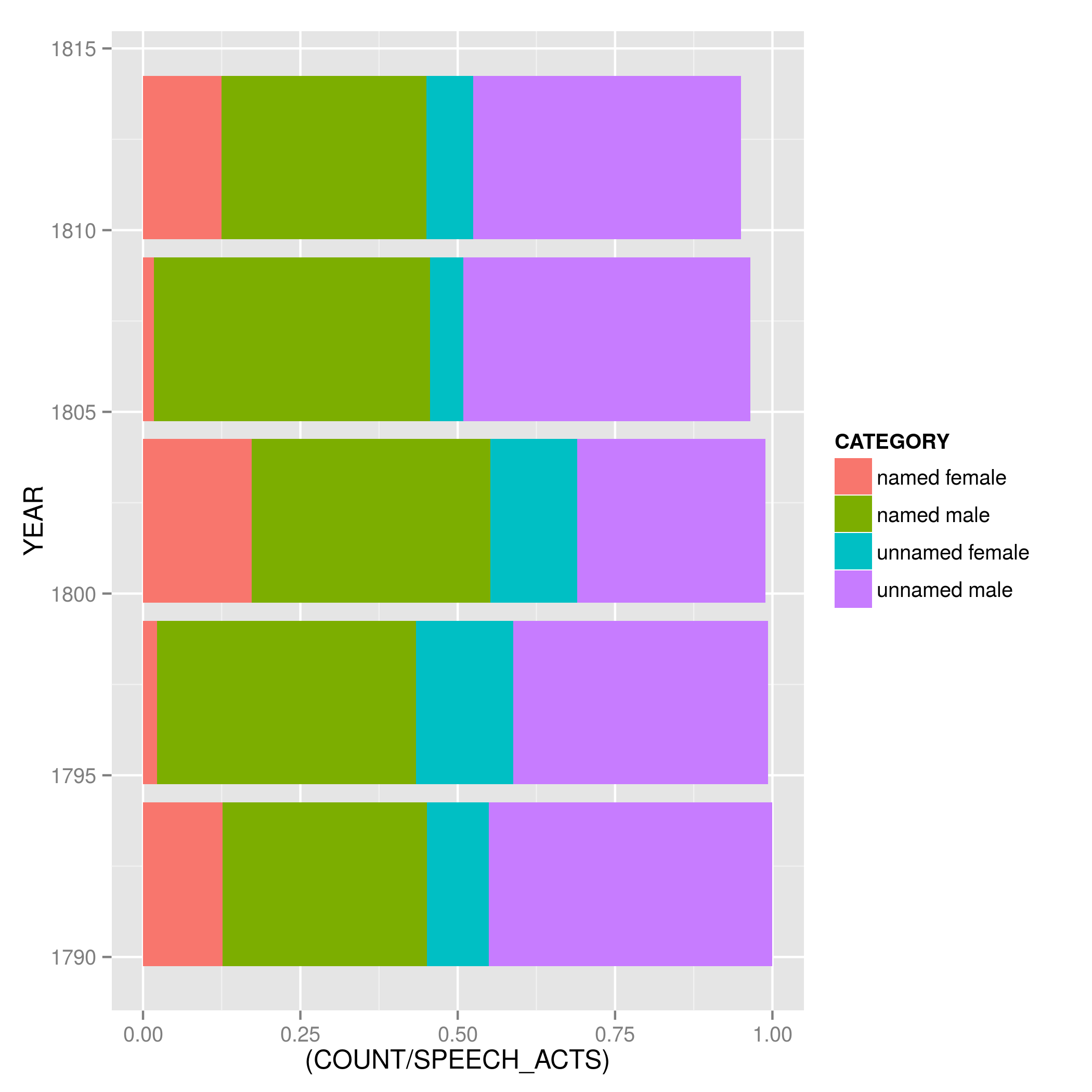
Figure Four (code, data shows every speech act, separated (relative to total speech acts) by whether the speaker is a named female, named male, unnamed female, or unnamed male in prints published by Samuel Fores (a Piccadilly based publisher) on five samples years: 1792, 1797, 1802, 1807, and 1812 (note: this isn’t entirely clear on the graph as I haven’t totally got my head around labelling axis in R yet…). There are bumps here but nothing substantial enough to suggest a longitudinal shift. However if we look at Figure Five (code, data), where the same data is presented relative this time to total prints, there is a clear growth in speech acts in prints from around 1.5 speech acts per prints to nearly 3 per print in 1812 (1797 may be an anomaly, but only a larger sample will confirm or otherwise. Note also, that these figures do take into account prints that contain no speech acts). And so overall there is more speaking going on in Fores prints and more unnamed (especially) male people doing the speaking.

Now this is just the data for one publisher and we are Likely see other patterns with other publishers. But Fores is a useful test case for two reasons: first, because circa 1790-1810 he is useful bell-weather for London satirical print publishing as he had during this time a strong and varied, if political focused, output; and second, because after 1810 he declined in prominence (exemplified by the fact that although his output was around 40 prints per year 1790-1805, only 13 prints are listed in BMSat for 1812).
What this points to then is change in the trade. If the relationship between unnamed and named doesn’t change much in Fores prints 1792-1812 (in the sample years at least) and if Fores represented a style of satirical prints common of the circa 1785-1810 Golden Age of Caricature – which he did – then new types of prints (perhaps more talky, as Figure Five suggests) likely account for the closer relationship between gender category words and ‘say-lemma’ after 1805 we see in Figure Three. As Brian Maidment has argued, the early 19th century was a volatile time for satirical printing with artist-engravers and publishers alike experimenting with form, style, and substance. My aim with this project is to show that by looking at those prints and George’s proxy descriptions in tandem our knowledge of both phenomena – late-Georgian satirical art and mid-twentieth century cataloguing – are enriched.
