
Since my last post on research using with the Catalogue of Political and Personal Satires in the British Museum (hereafter BMSat) as a dataset I’ve been working on various threads, including Named Entity Extraction (I hope to write about this in my next blog), extracting the words used when figures in the prints are ‘speaking’ (with variable success), and wrangling my initial thoughts, reflections, and experiments into something that has started to resemble publishable research (or at least something I’m happy to talk about in a research paper setting).
One thread I’ve also been pursuing with some success has been pulling together data on what people are doing in the prints (or least what BMSat as a proxy for the prints themselves says they are doing – and before you worry, yes I am working on how the results from analysis of this proxy maps to the original sources). When we look at the fifty most common lemma words for all the satires dated 1770-1830 (covering all of the entries made by Mary Dorothy George) the doing words that stand out are:
Rank Lemma Count (total 1123450) 5 stand 9847 7 wear 8096 10 say 6991 11 hold 5722 12 holding 4984 15 look 4564 18 dress 4388 20 sit 3698 22 saying 3211 44 seat 2234 48 lie 2119 49 point 2080
Now these aren’t perfect: a strong lemma for lie is ‘lying’ (count: 209) which – of course – has meanings both in sense of lying down on the floor and not telling the truth about stuff. Nevertheless, what is striking here is that aside from standing about and wearing things (which both animate and inanimate objects can do) there is lots of saying going on in the descriptions in BMSat. Indeed the combined total occurrences for the lemma say (said, say, says) and saying (saying, sayings) is 10202, the second highest of any action lemma (that is if we also combine hold and holding, which I do for the remainder of this post).
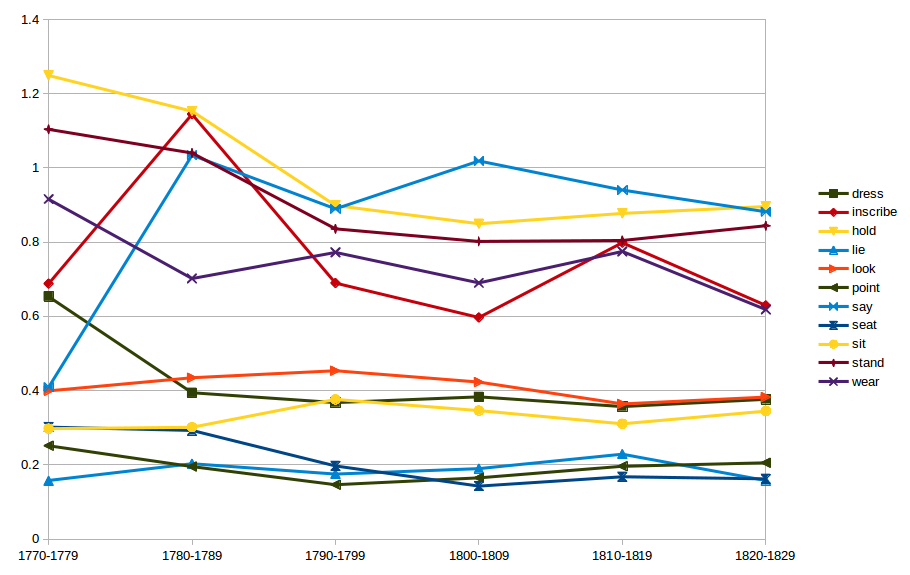
If we break down these occurrences of both the say and saying lemmas by decade, convert them from raw counts into percentage occurrence across the total words for the each decade (so `(word total / total words) x 100) we note that uses of the say lemma in BMSat peak in the 1780s, fall away in the 1790s and 1800s, and regain strength in the 1810s. We also note that the trajectory of the say lemma tracks two other lemmas: first 1770-1789 ‘inscribe’ and thereafter ‘wear’. Now as these percentages are by decade the data is very smoothed and should only be used to draw very preliminary conclusions (including, though, the conclusion I need to spend some time working on year by year percentages for the action words! – research as ever begets research…) *nevertheless* this data makes some sense: the initial tracking of ‘say’ and ‘inscribe’ map to what we know about the change in style of satirical prints in the 1770s-1780s from prints with legends to prints with speech bubbles; and it isn’t surprising that Dorothy George describes in BMSat about what characters are wearing and saying in relatively equal measure: these are, after all, the distinguishing characteristics of figures in Georgian satirical prints.
 To test whether spending more time creating fine-grained action data to better understand the say lemma is going to be worth it, I’ve also spent some time looking at the most common five words either side of ‘said’, ‘say’, ‘says’, and ‘saying’ (hereafter just ‘say’) in BMSat; otherwise described as 5L5R collocates. Again, the results make a lot of sense. Below I’ve flagged with ** the characters (both specific and non-specific) that appear to be speaking and/or spoken about based on this data:
To test whether spending more time creating fine-grained action data to better understand the say lemma is going to be worth it, I’ve also spent some time looking at the most common five words either side of ‘said’, ‘say’, ‘says’, and ‘saying’ (hereafter just ‘say’) in BMSat; otherwise described as 5L5R collocates. Again, the results make a lot of sense. Below I’ve flagged with ** the characters (both specific and non-specific) that appear to be speaking and/or spoken about based on this data:
Rank Total 5L 5R Word 1 529 447 82 right 2 451 411 40 left 3 404 25 379 ll **4 377 268 109 man** 5 292 12 280 oh 6 291 243 48 hand 7 259 21 238 shall 8 254 13 241 come 9 255 245 10 looks 10 257 255 2 inscribed **11 245 197 48 fox** 12 239 13 226 dear 13 236 183 53 behind 14 226 194 32 head 15 205 193 12 holding **16 198 77 121 lord** 17 199 188 11 holds 18 192 173 19 arm **19 191 135 56 john** 20 188 174 14 hands 21 190 184 6 hat 22 176 159 17 stands 23 162 152 10 shoulder **24 164 138 26 king** 25 154 3 151 ah 26 152 9 143 let **27 154 72 82 bull** **28 151 27 124 sir** **29 151 121 30 pitt** 30 148 18 130 say 31 146 27 119 good **32 145 20 125 mr** 33 140 19 121 dont 34 138 44 94 old 35 132 5 127 ha 36 135 104 31 looking 37 125 4 121 aye 38 132 107 25 says 39 122 115 7 arms 40 118 30 88 little **41 119 101 18 woman** **42 112 5 107 gentlemen** 43 118 117 1 profile 44 110 15 95 poor 45 107 6 101 ye 46 105 19 86 like 47 103 30 73 away 48 103 8 95 make 49 106 70 36 long **50 103 91 12 napoleon** **51 100 19 81 master** 52 103 74 29 cf 53 90 83 7 glass 54 88 85 3 turns 55 87 5 82 think 56 86 68 18 north 57 85 23 62 look **58 85 48 37 devil** **59 83 23 60 friend** 60 86 77 9 face 61 82 81 1 points 62 84 78 6 round 63 81 64 17 raised 64 86 79 7 large 65 82 75 7 paper **66 80 45 35 lady** **67 78 64 14 duke** 68 75 48 27 pointing 69 74 1 73 wish 70 74 37 37 eyes **71 78 56 22 men** **72 74 31 43 boy** 73 74 67 7 pocket **74 72 12 60 brother** 75 72 39 33 smile **76 73 54 19 mrs** 77 71 16 55 sic **78 71 53 18 prince** 79 72 59 13 wig 80 71 70 1 sword 81 69 8 61 know **82 69 20 49 jack** 83 71 66 5 extreme 84 71 34 37 stand **85 67 17 50 fellow** 86 66 1 65 got 87 65 3 62 pray 88 64 10 54 mind 89 63 33 30 expression 90 64 59 5 bag 91 62 5 57 pretty 92 62 54 8 nose 93 61 3 58 ve 94 62 15 47 great 95 66 64 2 wearing 96 59 45 14 whip 97 58 48 10 extended 98 59 48 11 breeches 99 59 17 42 st **100 57 53 4 sheridan**
Presenting this in the context of other 5L5R collocates of ‘say’ demonstrates how important characters are to speech acts recorded in BMSat and that there is value in distinguishing between 5L and 5R collocates: words from speech (‘oh’, ‘ye’, ‘ha’, and ‘aye’) and words that might open speech acts (‘dear’, ‘good’, ‘come’) are strong 5R; words associated with how something in being said such as ‘turns’ (“turns and says:…”) and ‘points’ (“points and says:…”) or describing the speaker and his or her possessions (‘sword’, ‘hat’, ‘pocket’) are strong 5L . And when we look at this more closely and start breaking the data down by decade we start seeing some interesting patterns. ‘John’ (presumably in most cases ‘Bull’), ‘Napoleon’, and to a less extent ‘King’ appear 5L of ‘say’ often in the first decade of the nineteenth century (ranked 2, 7 and 18 respectively): they have, presumably, a lot to say. Around the same time ‘Lord’ flips from being the speaker to the subject of things that are said (accounting for, one imagines, a steady presence of speech acts that begin “My lord, …”. And looking at ‘man’ and ‘woman’ – the subject of a previous post – we find the former appears within five words either side of ‘say’ more than twice as often as the latter. Hardly surprising. And yet for ‘man’ 71.1% of those occurrences appear 5L of ‘say’ and for ‘woman’ 84.9%, suggesting that when they appear in prints generic women (for of course this count takes no account of those speaking men and women described in BMSat by name or some other nomenclature) tend to speak.
There are other stories to tell from this data: the strength in the 1780s of ‘Fox’ as both a subject and instigator of speech and the steep decline of the word thereafter; the consistent words such as ‘dear’, ‘let’, and ‘oh’; and the sharp decline in ‘profile’ as a collocate of ‘say’ (over half as few occurrences in 1800-1830 as in the 1790s: are there, perhaps, fewer figures after 1800 ‘standing in profile saying “My lord, …”). Anyway, these are thoughts for another time.
If you are interested in how the lemmatisation and collocation work was done, my tool of preference at the moment is AntConc.

You must be logged in to post a comment.